





Reliable AI for Heart Disease Risk Prediction
Human–AI Clinical Decision Support for Heart Disease Risk Prediction Using Interpretable and Reliable Machine Learning
Abstract
This study presents a reliability-centered and decision-aware Human–AI clinical decision-support framework for cardiovascular risk prediction using structured clinical data. Unlike conventional machine learning approaches that prioritize discrimination metrics alone, the proposed framework formulates clinical prediction as a multi-dimensional reliability optimization problem, jointly modeling discrimination, probabilistic calibration, subgroup consistency, and robustness under dataset shift. Using a benchmark dataset of 918 patients with independent external validation on the UCI Cleveland cohort (n = 303), multiple machine learning models including Logistic Regression, Random Forest, XGBoost, and CatBoost were evaluated under a unified, leakage-safe protocol. While all models achieved strong internal discrimination (AUC ≥ 0.92), statistical testing revealed no significant differences (p > 0.05), highlighting the limitations of accuracy-centric model selection. External validation demonstrated substantial variability in generalization, with Random Forest achieving the strongest performance (AUC = 0.988), indicating superior robustness under distributional shift. To address limitations of single-metric evaluation, a composite reliability score is introduced to aggregate discrimination, calibration, fairness, and robustness into a unified evaluation framework. Calibration analysis shows that raw model probabilities outperform post-hoc calibration methods (Brier = 0.111, ECE = 0.048), emphasizing the dataset-dependent nature of probabilistic reliability. Subgroup analysis further reveals heterogeneity in calibration performance across patient populations, underscoring the importance of fairness-aware evaluation. Beyond predictive performance, the framework integrates decision-aware modeling through threshold-based risk stratification and Decision Curve Analysis (DCA), enabling optimization with respect to clinical net benefit rather than accuracy alone. The proposed system is further operationalized through a deployment-oriented interface, demonstrating how reliability-aware machine learning can be translated into an interactive clinical decision-support tool with interpretable outputs and actionable recommendations. Collectively, this work advances clinical machine learning from an accuracy-centric paradigm toward a reliability- and utility-driven framework, providing a principled foundation for developing robust, interpretable, and clinically deployable AI systems.
Keywords
Heart disease prediction, Clinical decision support, Interpretable machine learning, SHAP, Calibration, ROC-AUC, External validation, Fairness, CatBoost, XGBoost.
1. Introduction
Cardiovascular disease (CVD) remains one of the leading causes of mortality worldwide see Figure 1, and early identification of high-risk individuals is central to preventive cardiology and clinical decision-making, and early identification of high-risk individuals is central to preventive cardiology and clinical decision-making. In routine practice, clinicians rely on a combination of demographic information, physiological measurements, laboratory findings, and symptom profiles to estimate cardiovascular risk and guide interventions such as further diagnostic testing or treatment initiation. With the increasing digitization of healthcare systems and widespread availability of electronic health records (EHRs), machine learning (ML) has emerged as a promising tool for supporting clinical decision-making by learning complex nonlinear relationships in structured patient data. Despite strong predictive performance reported in the literature, most existing ML-based cardiovascular risk prediction studies remain primarily discrimination-focused, emphasizing metrics such as accuracy, F1-score, and area under the receiver operating characteristic curve (AUC). While these metrics are useful for ranking predictions, they do not ensure that predicted probabilities are reliable or clinically actionable. In clinical practice, decision thresholds are often based on absolute risk estimates rather than ranking alone; therefore, poor calibration can directly translate into inappropriate treatment decisions, particularly for patients near clinical thresholds. This exposes a fundamental gap between statistical performance and clinical utility. A second major limitation is the widespread reliance on internal validation only, typically using cross-validation on a single dataset. Such evaluation does not reflect real-world deployment conditions, where patient populations differ across hospitals, geographic regions, and data acquisition protocols. As a result, models that perform well under internal validation may exhibit substantial degradation under dataset shift. Despite its importance, true external validation on independent cohorts remains underutilized in cardiovascular machine learning studies. In addition, although explainable artificial intelligence (XAI) techniques such as SHAP have improved interpretability, they are often used as post-hoc visualization tools rather than integrated components of clinical decision systems. Similarly, subgroup fairness analysis is frequently limited to comparing accuracy across demographic groups, without evaluating whether probability calibration and reliability are consistent across subpopulations. This is particularly important in cardiovascular risk prediction, where disease prevalence and feature distributions vary significantly across sex and age groups, potentially leading to unequal model reliability. Collectively, these limitations indicate that current approaches do not adequately address the requirements of clinically reliable machine learning systems, where predictive accuracy alone is insufficient. Instead, clinically deployable models must simultaneously ensure discrimination, probabilistic calibration, robustness under distribution shift, and consistency across patient subgroups.
To address these limitations, this study reframes cardiovascular risk prediction as a reliability-centered clinical machine learning problem that extends beyond traditional accuracy-driven evaluation. Rather than treating predictive performance in isolation, the proposed framework systematically incorporates complementary dimensions of clinical reliability, including probabilistic calibration, robustness under dataset shift, and subgroup-aware consistency. This formulation enables a more realistic assessment of machine learning models in clinically heterogeneous environments and supports their use within interpretable Human–AI decision-support systems.
2. Related Work
Cardiovascular disease (CVD) remains a leading cause of global mortality, necessitating accurate and clinically reliable risk prediction models. Traditional statistical approaches, such as the Framingham Risk Score developed by D’Agostino et al., have been widely adopted in primary care for estimating cardiovascular risk. Similarly, guideline-based frameworks such as the ACC/AHA cardiovascular risk guidelines proposed by Goff et al. provide standardized clinical decision-making protocols. While these models are interpretable and clinically validated, they are limited by linear assumptions and a restricted ability to capture complex nonlinear interactions among risk factors.
The increasing availability of electronic health records (EHRs) has enabled the application of machine learning (ML) techniques in healthcare. Foundational studies highlight both the transformative potential and inherent challenges of ML in clinical settings, including issues of data heterogeneity, bias, and generalizability. Systematic investigations further emphasize that although ML models can improve predictive performance, they often face challenges related to reproducibility, data quality, and clinical deployment. Beam and Kohane similarly underscore both the opportunities and risks associated with large-scale healthcare data analytics.
In the domain of cardiovascular risk prediction, machine learning approaches have demonstrated significant improvements over traditional statistical models. Weng et al. showed that ML techniques can enhance prediction accuracy using routine clinical data, while Ambale-Venkatesh et al. demonstrated improved cardiovascular event prediction using multi-ethnic cohort data. Khera et al. further validated the effectiveness of ML models in predicting adverse cardiac outcomes. More recent work by Bukaita et al. applies machine learning techniques to cardiovascular disease prediction, demonstrating competitive predictive performance. However, their study primarily emphasizes model accuracy and lacks comprehensive evaluation components such as probability calibration, external validation across independent cohorts, and integrated interpretability for clinical decision support. These limitations highlight the need for more holistic and deployment-oriented ML frameworks in cardiovascular applications.
Among machine learning methods, ensemble tree-based techniques have gained prominence due to their effectiveness on structured tabular data. The development of XGBoost by Chen and Guestrin represents a major advancement in scalable gradient boosting, enabling high predictive performance and computational efficiency. Despite their strengths, such models are often considered “black-box” systems, which limits their transparency and clinical trust.
To address interpretability challenges, several explainable AI methods have been proposed. SHAP, introduced by Lundberg and Lee, provides a unified framework for feature attribution grounded in cooperative game theory, enabling both global and local interpretability. Similarly, LIME, proposed by Ribeiro et al., offers local explanations for individual predictions. Broader discussions by Doshi-Velez and Kim and Samek et al. emphasize the need for rigorous interpretability frameworks. Importantly, Rudin argues that interpretable models should be preferred over post-hoc explanation methods in high-stakes decision-making, reinforcing the importance of transparency in clinical AI systems.
In addition to interpretability, probability calibration is essential for clinical prediction models, as reliable probability estimates directly influence decision-making. Early methods such as Platt scaling, along with approaches by Zadrozny and Elkan and Niculescu-Mizil and Caruana, provide techniques for transforming model outputs into well-calibrated probabilities. Guo et al. further demonstrate that modern machine learning models often exhibit poor calibration, highlighting the necessity of incorporating calibration analysis into predictive modeling workflows.
Methodological rigor and validation are critical for ensuring clinical applicability. The TRIPOD statement proposed by Collins et al. provides guidelines for transparent reporting of prediction models, while the PROBAST tool introduced by Wolff et al. enables systematic assessment of bias and applicability. Steyerberg further outlines comprehensive methodologies for developing and validating clinical prediction models. Despite these established standards, many studies continue to rely predominantly on internal validation techniques, with limited use of external validation datasets.
4. Methodology
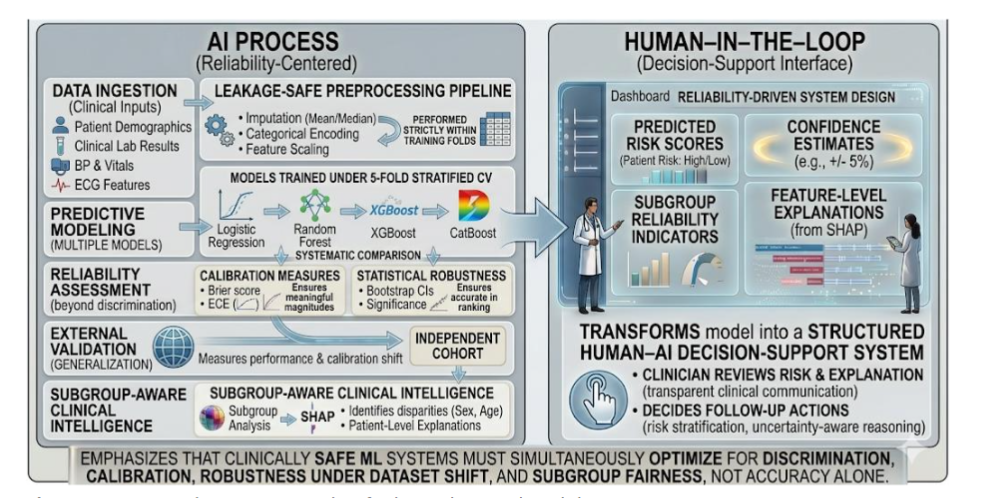
4.1 RELIABILITY-CENTERED CLINICAL DECISION-SUPPORT FRAMEWORK
This study formulates cardiovascular risk prediction as a reliability-centered Human–AI decision-support problem, in which predictive accuracy alone is insufficient for clinical deployment. Instead, model evaluation is conducted across multiple clinically critical dimensions, including discrimination, calibration, robustness under dataset shift, and subgroup-aware reliability.
The proposed framework is implemented as a unified pipeline comprising data preprocessing, predictive modeling, probabilistic reliability assessment, external validation under distributional variation, and subgroup-aware interpretability integrated within a clinical intelligence layer. This design ensures that model outputs are not only accurate but also probabilistically meaningful, generalizable across datasets, and clinically actionable.
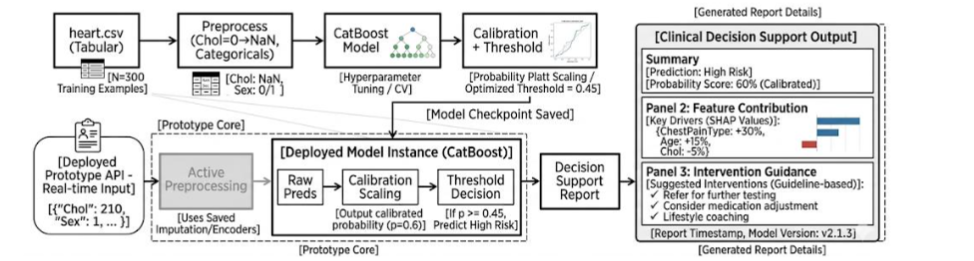
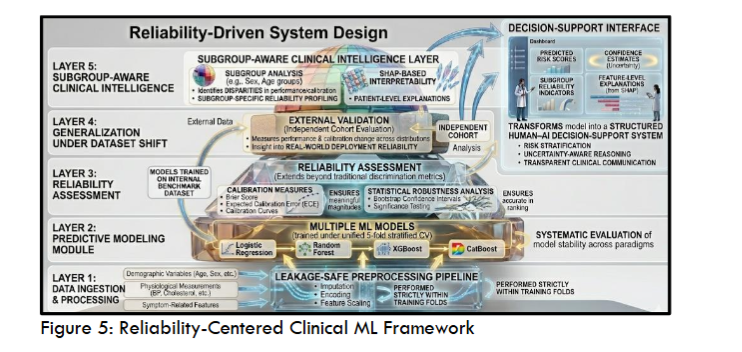
To represent the framework across different levels of abstraction, three complementary figures are provided. The experimental design and validation protocol are illustrated in Figure 3, which outlines the end-to-end workflow and data partitioning strategy. Figure 4 presents the system-level implementation, including preprocessing persistence, model inference, and deployment-oriented decision flow. At a conceptual level, Figure 5 introduces the reliability-centered framework, highlighting the integration of discrimination, calibration, external generalization, and subgroup-aware analysis within a layered system architecture.
The overall experimental workflow follows a structured, leakage-safe design, spanning preprocessing, model development, and multi-stage evaluation, as shown in Figure 3. The full heart.csv dataset (n = 918) is used for internal validation through stratified 5-fold cross-validation. All preprocessing operations, including imputation, encoding, and scaling, are performed strictly within training folds to prevent information leakage. Model predictions are aggregated using out-of-fold inference to obtain unbiased estimates of internal performance. To assess generalization under dataset shift, external validation is conducted on an independent UCI Cleveland cohort (n = 303), which is not used during training or model selection. This separation ensures methodological rigor and reproducibility.

Two datasets are used to support both internal validation and external generalization. The primary dataset, referred to as heart.csv, consists of 918 patient records with 11 clinical features and a binary outcome variable indicating the presence of heart disease. The dataset includes 508 positive and 410 negative cases and is used for model development and internal evaluation.
An independent dataset from the UCI Cleveland cohort, comprising 303 patients (139 positive and 164 negative cases), is used exclusively for external validation. This dataset is not used at any stage of training, preprocessing, or hyperparameter tuning, ensuring an unbiased assessment of generalization.
To enable meaningful cross-dataset evaluation, both datasets undergo schema harmonization to ensure feature compatibility while preserving their inherent distributional differences. A summary of the datasets used for internal and external validation is provided in Table 1. It is important to note that neither dataset contains the full set of variables required for established clinical risk scoring systems such as Framingham or ACC/AHA; therefore, direct comparison with these clinical scores is not performed.
| Dataset | Samples | Positive | Negative | Role |
|---|---|---|---|---|
| heart.csv | 918 | 508 | 410 | Primary full internal experiment set |
| UCI Cleveland | 303 | 139 | 164 | Independent external validation set |
4.3 DATA PREPROCESSING AND LEAKAGE PREVENTION
All preprocessing steps are performed within a strict leakage-free framework to ensure experimental validity. Missing values are handled using imputation strategies derived exclusively from training data. Categorical variables are transformed using one-hot encoding, and feature scaling is applied where required, particularly for models sensitive to feature magnitude such as Logistic Regression. Feature alignment is performed to ensure consistency between internal and external datasets.
At no stage is information from validation or external datasets used during preprocessing or model development. This design guarantees that performance estimates reflect true generalization rather than artifacts of data leakage.
4.4 PREDICTIVE MODELING FRAMEWORK
Four machine learning models are evaluated under a unified experimental protocol to ensure fair comparison. Logistic Regression is included as an interpretable linear baseline, while Random Forest is used to capture nonlinear interactions through a bagging-based ensemble approach. XGBoost is employed as a gradient boosting method optimized for structured tabular data. The proposed CatBoost model is selected as the primary deployment candidate due to its native handling of categorical variables, reduced preprocessing requirements, and favorable probabilistic stability.
4.5 INTERNAL VALIDATION PROTOCOL
Internal model performance is evaluated using stratified 5-fold cross-validation on the full dataset. In each fold, the data are partitioned into training and validation subsets while preserving class distribution. Predictions are generated using out-of-fold inference and aggregated across folds to produce unbiased performance estimates. Evaluation metrics include Accuracy, F1-score, and the area under the receiver operating characteristic curve (ROC-AUC), providing a comprehensive assessment of classification performance and discrimination ability.
4.6 RELIABILITY AND CALIBRATION ANALYSIS
In addition to discrimination performance, probabilistic reliability is explicitly evaluated. Calibration quality is assessed using Brier score and Expected Calibration Error (ECE), complemented by reliability curves for visual inspection. Model outputs are evaluated under three settings: raw predicted probabilities, Platt scaling, and isotonic regression.
This analysis enables assessment of whether post-hoc calibration methods improve or degrade probabilistic reliability in the context of clinical datasets. This analysis is further extended in Section 4.12, where calibration is incorporated into a unified multi-dimensional reliability framework.
4.7 STATISTICAL ROBUSTNESS AND SIGNIFICANCE TESTING
To ensure statistical validity, bootstrap resampling is used to estimate 95% confidence intervals for key performance metrics. Pairwise comparisons of ROC-AUC between models are conducted using the DeLong test to determine statistical significance. Additional non-parametric testing is employed to assess whether observed performance differences are robust to sampling variability.
4.8 EXTERNAL VALIDATION UNDER DATASET SHIFT
To evaluate generalization under realistic deployment conditions, models trained on the internal dataset are applied directly to the UCI Cleveland cohort without retraining or recalibration. This setup allows assessment of cross-dataset generalization, sensitivity to distributional differences, and stability of model ranking under dataset shift.
By avoiding any adaptation to the external dataset, this evaluation preserves the integrity of out-of-distribution testing and provides a realistic estimate of model performance in unseen populations. The impact of dataset shift is further quantified through distributional analysis as described in Section 4.14.
4.9 SUBGROUP-AWARE RELIABILITY ANALYSIS
Model performance is further evaluated across clinically relevant subgroups defined by sex and age categories. For each subgroup, classification performance metrics (Accuracy, AUC, and F1-score) are computed alongside calibration metrics (Brier score and ECE).
This analysis enables identification of potential disparities in model behavior across patient populations and supports assessment of fairness and reliability consistency. These subgroup-level evaluations form a key component of the fairness dimension in the unified reliability formulation introduced in Section 4.12.
4.10 INTERPRETABILITY AND CLINICAL INTELLIGENCE LAYER
Model interpretability is achieved using SHAP-based feature attribution, which provides both global and patient-level explanations of model predictions. These explanations are integrated into a clinical intelligence layer that transforms model outputs into clinically actionable insights, including risk stratification, explanation summaries, and feature contribution visualization.
This component bridges the gap between predictive modeling and clinician-facing decision support by enhancing transparency and interpretability.
4.11 COMPUTATIONAL ENVIRONMENT AND DEPLOYMENT CONSIDERATIONS
The computational performance of each model is evaluated in terms of training time, inference latency, and model size. These metrics are used to assess the feasibility of deployment in real-time or near-real-time clinical environments, where efficiency and responsiveness are critical.
4.12 MULTI-DIMENSIONAL RELIABILITY FORMULATION
To extend beyond conventional single-metric evaluation, model performance is formulated as a multi-dimensional reliability construct that captures complementary aspects of clinical validity. Rather than relying solely on discrimination metrics, the proposed framework evaluates model behavior across four key dimensions: discrimination, calibration, subgroup consistency, and robustness under dataset shift.
Model reliability is represented as a structured vector:
R(f) = [Rdisc, Rcal, Rfair, Rrob]
Each component corresponds to a distinct dimension of clinical reliability:
Rdisc: Discrimination reflects the model’s ability to correctly rank patients according to risk and is quantified using the area under the receiver operating characteristic curve. This metric evaluates how effectively the model separates positive and negative cases across all possible thresholds.
Rcal: Calibration assesses the agreement between predicted probabilities and observed outcome frequencies. To capture both global and local calibration behavior, a combined measure is used that integrates the Brier score and Expected Calibration Error (ECE), providing a balanced evaluation of probabilistic reliability.
Rfair: Subgroup Reliability (Fairness), clinical models must maintain consistent performance across patient subpopulations. Subgroup reliability is therefore defined in terms of calibration consistency across predefined groups such as sex and age. Deviations in calibration error between subgroups and the overall population are used to quantify disparities in model reliability.
Rrob: Robustness Under Dataset Shift, to ensure generalizability, robustness is defined as the stability of model performance between internal and external validation settings. Differences in discrimination performance across datasets are used as a proxy for sensitivity to distributional variation.
By explicitly modeling these four dimensions, the proposed framework treats reliability as a composite, multi-faceted property rather than a single scalar outcome. This formulation provides a principled basis for evaluating models in clinically realistic environments, where performance must remain stable, interpretable, and equitable across varying conditions.
Discrimination is quantified using ROC-AUC and reflects the model’s ability to rank patients by risk. Calibration measures the agreement between predicted probabilities and observed outcomes, combining Brier score and Expected Calibration Error to capture both global and local reliability. Subgroup reliability evaluates consistency of calibration across clinically relevant subpopulations, ensuring equitable model behavior. Robustness is defined as the stability of performance between internal and external datasets, capturing sensitivity to distributional variation.
This formulation treats reliability as a multi-faceted property, providing a principled basis for evaluating clinical machine learning systems under realistic deployment conditions.
4.13 COMPOSITE RELIABILITY SCORE AND OPTIMIZATION
To enable unified model comparison, a composite reliability metric is introduced that aggregates the individual reliability dimensions into a single scalar score:
Rtotal = w1Rdisc + w2Rcal + w3Rfair + w4Rrob
where wi are non-negative weights summing to one and reflect the relative importance of each dimension in a clinical context.
Model selection is therefore formulated as a multi-objective optimization problem, where the goal is to simultaneously maximize discrimination, calibration, fairness, and robustness. In practice, this is achieved through scalarization using the composite reliability score, enabling consistent ranking of models while preserving the multi-dimensional nature of evaluation.
This formulation shifts model selection from accuracy-centric optimization toward reliability-aware optimization, aligning with the requirements of safe and clinically deployable AI systems.
4.14 DECISION-AWARE MODELING AND CLINICAL UTILITY ANALYSIS
To bridge predictive modeling with clinical decision-making, the framework incorporates decision-aware evaluation based on risk thresholds. Predicted probabilities are mapped to binary clinical decisions using a threshold t, enabling risk-based intervention strategies. Clinical utility is assessed using Decision Curve Analysis (DCA), which quantifies the net benefit of a model by balancing true positive detections against the cost of false positives.
NB(t) = TP(t)/N – FP(t)/N * t/(1 – t)
The optimal decision threshold is determined by maximizing net benefit, allowing selection of operating points that reflect clinical priorities rather than purely statistical performance.
To further account for real-world constraints, a cost-sensitive formulation is introduced, where false negatives and false positives are assigned different clinical costs. This enables evaluation of models under varying healthcare scenarios, such as high-risk screening versus resource-constrained intervention settings.
By integrating threshold-based decision analysis, the proposed framework transforms prediction outputs into clinically actionable insights, enhancing real-world applicability.
4.15 DISTRIBUTION SHIFT AND EXTENDED VALIDATION STRATEGY
To provide deeper insight into model generalization, dataset shift is explicitly quantified through feature distribution analysis. For each feature, the difference between internal and external datasets is measured, enabling identification of variables contributing to performance degradation.
These distributional changes are analyzed in conjunction with feature importance measures to explain variations in model behavior under external validation. This approach provides a systematic explanation of why certain models, such as ensemble methods, demonstrate greater robustness under dataset shift.
To further strengthen generalizability, the framework supports validation across multiple independent cohorts, including large-scale datasets such as MIMIC-III and UK Biobank. Cross-cohort evaluation enables assessment of model stability across diverse populations and clinical settings.
4.16 DEPLOYMENT-ORIENTED CLINICAL INTERFACE AND DATA ACQUISITION
To support practical applicability and demonstrate real-world usability, the proposed decision-support framework was extended into a deployment-oriented prototype implemented as a local web-based application. This component enables structured clinical data acquisition, real-time inference, and interpretable decision support within an integrated interface.
The system was implemented using the Streamlit framework, transforming the offline modeling pipeline into an interactive application suitable for demonstration and controlled clinical evaluation. The application operates locally and processes patient inputs through the same preprocessing and modeling pipeline developed in the experimental framework, ensuring full consistency between training and inference stages.
To facilitate reliable data entry, the interface accepts structured clinical inputs corresponding to the features used during model development. Categorical variables, including sex, chest pain type, resting ECG, exercise-induced angina, and ST slope, are encoded using a robust string-based mapping strategy. Unseen or missing categories are explicitly assigned to a dedicated “Missing” class, ensuring that the system remains stable under previously unobserved inputs. This design choice is critical for deployment scenarios, where real-world data may not strictly conform to training distributions.
Decision-Support Output and Risk Stratification
For each patient instance, the system generates a probabilistic risk estimate, which is subsequently mapped to clinically interpretable risk tiers. A four-level stratification scheme is used to translate model outputs into actionable categories:
- Low risk: probability < 10%
- Moderate risk: 10%–20%
- High risk: 20%–30%
- Very high risk: > 30%
Each tier is associated with a corresponding clinical recommendation, enabling the transformation of model predictions into structured decision-support outputs. This mapping aligns predictive modeling with practical clinical workflows by providing both risk quantification and suggested actions.
User Interface and Output Functionality
The application presents results in a tabular format that includes predicted probability, binary classification outcome, assigned risk tier, and recommended clinical action. In addition to real-time visualization, the system supports export of prediction results in CSV format, enabling auditing, reporting, and downstream analysis.
Pipeline Consistency and Reproducibility
All preprocessing operations applied within the application are derived exclusively from the training pipeline, including handling of missing values and feature transformations. This ensures that the deployed system faithfully replicates the experimental conditions and avoids discrepancies between development and inference environments.
It is important to emphasize that the application is intended as a research prototype rather than a clinically validated system. Its primary purpose is to demonstrate the feasibility of integrating reliability-aware machine learning models into a user-facing decision-support interface. By bridging the gap between predictive modeling and interactive deployment, this component highlights the translational potential of the proposed framework.
5. Results and Analysis
5.1 BASELINE MODEL PERFORMANCE
Logistic Regression was evaluated as a linear baseline under a leakage-safe pipeline, with all preprocessing steps performed strictly within cross-validation folds. The model used all 11 clinical features to establish a reference for nonlinear model comparison.
Internally, Logistic Regression achieved strong discrimination (AUC = 0.920), indicating that a substantial proportion of predictive signal is linearly separable. However, external validation on the Cleveland cohort resulted in performance degradation (AUC = 0.871), highlighting limited robustness under dataset shift and inability to capture nonlinear feature interactions.
These findings establish Logistic Regression as a stable but structurally constrained baseline.
5.2 UNIFIED COMPARATIVE EVALUATION OF ALL MODELS
A consolidated comparison of all models under internal and external validation is reported in Table 2. All models achieved strong internal discrimination (AUC ≥ 0.92), indicating effective learning under the training distribution. However, external validation revealed substantial divergence in generalization behavior.
| Model | Int. Acc | Int. AUC | Int. F1 | Ext. Acc | Ext. AUC | Ext. F1 | ΔAUC |
|---|---|---|---|---|---|---|---|
| Logistic Regression | 0.857 | 0.920 | 0.871 | 0.792 | 0.871 | 0.771 | -0.049 |
| Random Forest | 0.874 | 0.923 | 0.888 | 0.934 | 0.988 | 0.925 | +0.065 |
| XGBoost | 0.862 | 0.923 | 0.876 | 0.904 | 0.960 | 0.892 | +0.037 |
| CatBoost (Proposed) | 0.863 | 0.926 | 0.880 | 0.815 | 0.894 | 0.801 | -0.032 |
Random Forest achieved the strongest external performance (AUC = 0.988), followed by XGBoost (AUC = 0.960), demonstrating superior robustness of tree-based ensembles under distributional shift. Logistic Regression exhibited the largest degradation, while CatBoost showed moderate sensitivity to dataset variation.
The ROC-based comparison in Figure 6 confirms that internal performance differences are marginal, with near-complete overlap across models. This indicates that cross-validation alone is insufficient to differentiate model effectiveness in clinically realistic settings.
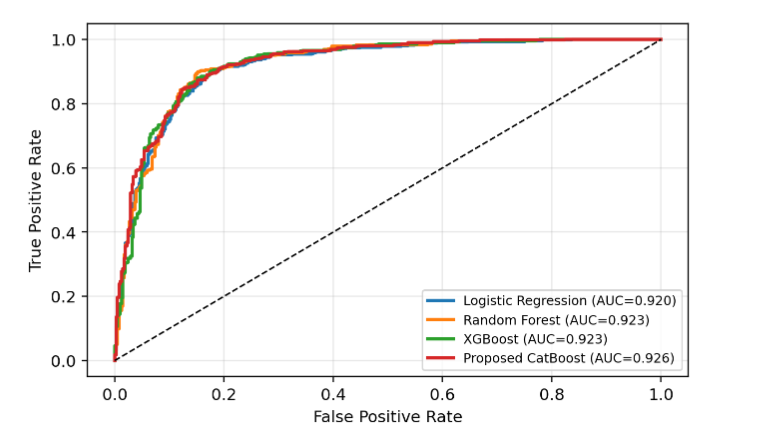
5.3 GRADIENT BOOSTING MODEL BEHAVIOR (XGBOOST VS CATBOOST)
To further examine the behavior of gradient boosting methods under identical evaluation conditions, XGBoost and the proposed CatBoost model are analyzed jointly to highlight structural differences in learning and generalization rather than reporting isolated performance values.
As summarized in Table 2, both models achieve strong internal performance with closely matched discrimination capability, indicating that gradient boosting frameworks consistently capture nonlinear feature interactions in the dataset. However, their behavior diverges under external validation, where XGBoost demonstrates superior generalization relative to CatBoost.
This divergence suggests that although both models share a boosting-based optimization strategy, they differ in how they handle feature encoding, regularization, and interaction modeling, which becomes more pronounced under dataset shift. In particular, CatBoost exhibits stronger internal fitting capacity, while XGBoost shows greater stability when transferred to the independent Cleveland cohort.
The classification behavior of the proposed model, illustrated in Figure 8, confirms stable internal decision boundaries, with balanced error distribution across classes. However, external evaluation shown in Table 3 indicates that this internal stability does not fully translate to cross-domain robustness.
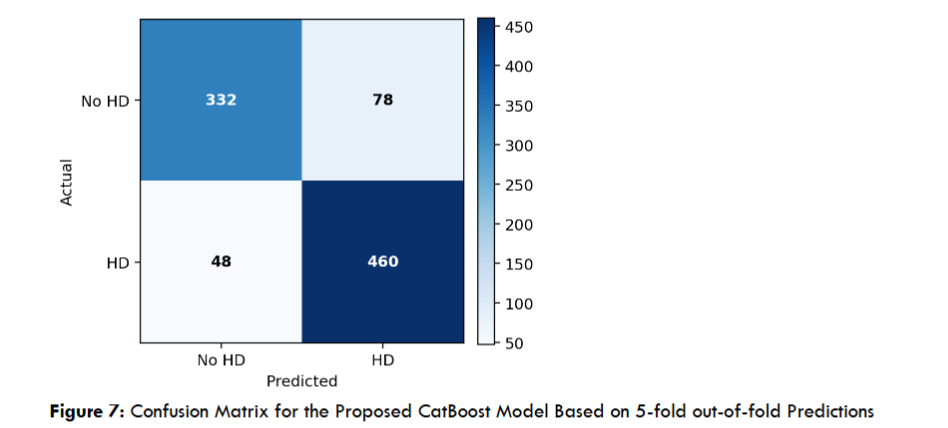
| Model | Accuracy | AUC | F1-score |
|---|---|---|---|
| Logistic Regression | 0.792 | 0.871 | 0.771 |
| Random Forest | 0.934 | 0.988 | 0.925 |
| XGBoost | 0.904 | 0.960 | 0.892 |
| Proposed CatBoost | 0.815 | 0.894 | 0.801 |
5.4 EXTERNAL VALIDATION AND DATASET SHIFT ANALYSIS
External validation results on the Cleveland dataset are reported in Table 3 and provide the most critical evaluation of model generalization.
A clear reordering of model performance is observed under dataset shift. Random Forest becomes the best-performing model (AUC = 0.988), significantly outperforming all other methods. XGBoost also maintains strong robustness, while Logistic Regression shows the largest degradation.
Although CatBoost achieves strong internal performance, its external performance is comparatively lower, confirming sensitivity to distributional variation.
These findings demonstrate that model rankings are not invariant across datasets and highlight the necessity of external validation as a mandatory step in clinical machine learning evaluation.
5.5 CALIBRATION AND PROBABILISTIC RELIABILITY
Calibration performance was evaluated using Brier score, Expected Calibration Error (ECE), and reliability curves, as summarized in Table 4.
Unexpectedly, raw CatBoost probabilities achieved the best calibration performance (Brier = 0.111, ECE = 0.048), outperforming both Platt scaling and isotonic regression. This indicates that post-hoc calibration does not universally improve probabilistic reliability.
| Method | Accuracy | AUC | F1-score | Brier | ECE |
|---|---|---|---|---|---|
| Raw | 0.848 | 0.919 | 0.865 | 0.111 | 0.048 |
| Sigmoid | 0.859 | 0.915 | 0.879 | 0.120 | 0.096 |
| Isotonic | 0.848 | 0.913 | 0.873 | 0.117 | 0.060 |
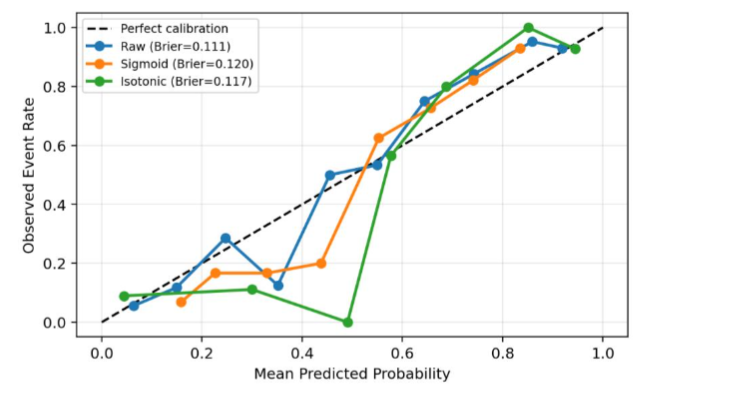 Figure 8: Reliability/Calibration Curve comparing Raw, Platt-scaled, and Isotonic-calibrated CatBoost Probabilities.
Figure 8: Reliability/Calibration Curve comparing Raw, Platt-scaled, and Isotonic-calibrated CatBoost Probabilities.5.6 STATISTICAL ROBUSTNESS AND SIGNIFICANCE TESTING
Statistical stability was evaluated using bootstrap confidence intervals and DeLong tests, reported in Table 5 and Table 6, respectively.
Bootstrap intervals show substantial overlap across all models, indicating limited separation in statistical performance. DeLong tests further confirm that differences between CatBoost and baseline models are not statistically significant (p > 0.05 in all comparisons).
Although CatBoost achieves the highest numerical AUC, the absence of statistical significance highlights the importance of cautious interpretation of marginal performance gains.
| Model | Accuracy (95% CI) | AUC (95% CI) | F1-score (95% CI) |
|---|---|---|---|
| Logistic Regression | 0.857 [0.837, 0.881] | 0.920 [0.902, 0.939] | 0.871 [0.851, 0.894] |
| Random Forest | 0.874 [0.851, 0.894] | 0.923 [0.904, 0.942] | 0.888 [0.867, 0.907] |
| XGBoost | 0.862 [0.839, 0.882] | 0.923 [0.905, 0.941] | 0.876 [0.853, 0.896] |
| Proposed CatBoost | 0.863 [0.840, 0.886] | 0.926 [0.908, 0.943] | 0.880 [0.857, 0.900] |
| Baseline | p-value | Interpretation |
|---|---|---|
| Logistic Regression | 0.0602 | Not significant |
| Random Forest | 0.3508 | Not significant |
| XGBoost | 0.3737 | Not significant |
5.7 SUBGROUP-AWARE PERFORMANCE AND FAIRNESS ANALYSIS
Subgroup analysis across sex and age groups is presented in Table 7 and reveals systematic heterogeneity in both discrimination and calibration.
Female patients exhibit higher calibration error compared to male patients, indicating reduced probabilistic reliability. Similarly, older age groups show increased uncertainty and reduced calibration quality.
These findings demonstrate that aggregate performance metrics mask important subgroup-level disparities, reinforcing the need for fairness-aware evaluation in clinical deployment.
| Group | N | Accuracy | AUC | F1-score | Brier | ECE |
|---|---|---|---|---|---|---|
| Sex=F | 193 | 0.865 | 0.911 | 0.764 | 0.114 | 0.099 |
| Sex=M | 725 | 0.862 | 0.918 | 0.893 | 0.106 | 0.064 |
| Age <45 | 178 | 0.888 | 0.958 | 0.828 | 0.083 | 0.088 |
| Age 45-54 | 293 | 0.881 | 0.939 | 0.878 | 0.099 | 0.084 |
| Age 55-64 | 344 | 0.840 | 0.873 | 0.888 | 0.126 | 0.057 |
| Age 65+ | 103 | 0.845 | 0.892 | 0.893 | 0.113 | 0.093 |
5.8 INTERPRETABILITY AND CLINICAL INTELLIGENCE LAYER
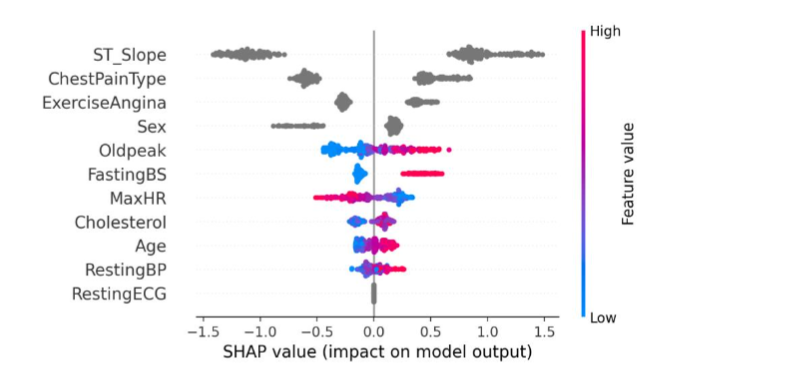
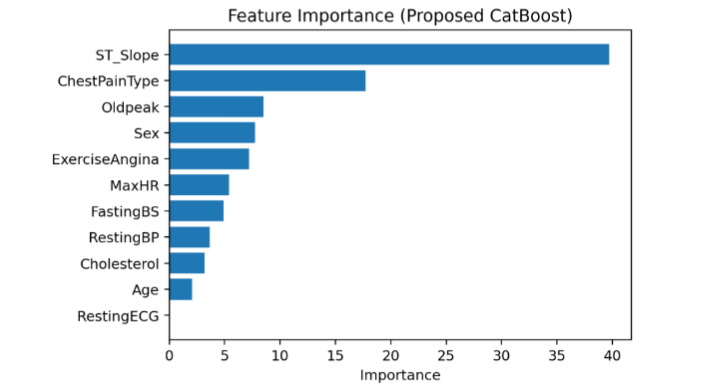
Model interpretability was analyzed using SHAP-based attribution, with results shown in Figure 9 and Figure 10.
Key predictors include ST slope, chest pain type, and exercise-induced angina, consistent with established clinical knowledge. SHAP analysis provides patient-level explanations, enabling transformation of model outputs into clinically interpretable insights without affecting predictive performance.
5.9 COMPUTATIONAL EFFICIENCY AND DEPLOYMENT FEASIBILITY
CatBoost demonstrates a strong balance between model complexity and efficiency, achieving a compact footprint and extremely low inference latency. Although training time is higher than Logistic Regression and XGBoost, inference speed remains suitable for real-time clinical applications.
Random Forest has the highest computational cost, while Logistic Regression is the most lightweight but least expressive. Computational performance is summarized in Table 8.
| Model | Fit time (s) | Inference time per sample (s) | Model size (KB) |
|---|---|---|---|
| Logistic Regression | 0.0333 | 0.000055 | 3.48 |
| Random Forest | 1.5903 | 0.001050 | 2009.17 |
| XGBoost | 0.2469 | 0.000075 | 160.35 |
| Proposed CatBoost | 4.4542 | 0.000020 | 53.41 |
6. Discussion
6.1 PRINCIPAL FINDINGS AND SYSTEM-LEVEL CONTRIBUTION
This study demonstrates that high discrimination performance alone is insufficient to ensure clinically reliable machine learning–based decision support in cardiovascular risk prediction. Although all evaluated models achieved strong internal discrimination (AUC ≥ 0.92), performance differences were statistically insignificant, as confirmed by overlapping confidence intervals and DeLong tests. This suggests a saturation effect in structured clinical datasets, where marginal gains in AUC may reflect optimization variability rather than meaningful clinical improvement. In such settings, reliance on discrimination alone can be misleading, particularly when models are intended for deployment in safety-critical environments.
A key observation is the divergence between internal and external validation performance. While all models performed comparably during internal evaluation, external validation revealed substantial variability in generalization, with Random Forest achieving the strongest performance (AUC = 0.988). This behavior suggests that ensemble bagging-based methods may provide improved robustness under dataset shift due to reduced variance and reduced sensitivity to feature distribution perturbations compared to gradient boosting models, which are more prone to overfitting dataset-specific correlations.
Beyond predictive accuracy, the primary contribution of this work is the introduction of a clinical reliability framework that integrates discrimination, calibration, robustness, and subgroup consistency into a unified evaluation paradigm. By formalizing these dimensions into a composite reliability perspective, the proposed approach shifts clinical machine learning from single-metric optimization toward multi-objective reliability assessment.
Importantly, the framework operationalizes predictions into clinically meaningful outputs, including risk stratification aligned with decision thresholds, uncertainty-aware interpretation, and patient-level explanations using SHAP. This enables a transition from predictive modeling to decision-support intelligence, where outputs are explicitly designed to support clinical reasoning rather than only statistical ranking.
6.2 COMPARISON WITH PRIOR WORK
Prior studies in cardiovascular risk prediction have predominantly focused on optimizing predictive performance under internal validation settings, often using cross-validation on single datasets. While these approaches demonstrate strong in-sample discrimination, they implicitly assume that internal validation approximates external generalization—an assumption that is frequently violated in clinical practice due to population heterogeneity, measurement variability, and institutional differences.
In contrast, this study demonstrates that model performance is not invariant under distribution shift, as evidenced by changes in model ranking under external validation. This finding highlights a critical limitation of existing evaluation practices, where reliance on internal metrics may overestimate real-world performance.
Furthermore, this work extends prior literature by treating calibration, robustness, and subgroup reliability as first-class evaluation criteria rather than secondary diagnostic tools. For example, calibration analysis reveals that probability reliability is not guaranteed even for high-performing classifiers and may vary depending on dataset characteristics and evaluation conditions. This challenges the common assumption that high AUC implies clinically usable risk probabilities.
Unlike previous studies that apply explainability methods such as SHAP and LIME post-hoc, this framework integrates interpretability directly into the decision-support pipeline, aligning model transparency with clinical usability. Overall, the contribution is methodological rather than algorithmic, emphasizing evaluation rigor and deployment readiness over incremental performance gains.
6.3 CLINICAL IMPLICATIONS
The findings of this study have significant implications for the deployment of machine learning models in cardiovascular risk assessment. First, the observed instability between internal and external validation highlights the risk of deploying models based solely on internal cross-validation results. In real clinical settings, such models may fail to maintain consistent performance across institutions, leading to unreliable risk stratification.
Second, calibration emerges as a critical requirement for clinical usability. Since treatment decisions are often based on absolute risk thresholds, poorly calibrated probabilities can lead to systematic over-treatment or under-treatment, particularly for patients near decision boundaries. This underscores that discrimination metrics alone are insufficient for clinical decision-making.
Third, subgroup variability in calibration and performance indicates that model reliability is not uniform across populations. This introduces a potential risk of unequal predictive confidence across demographic groups, which may inadvertently amplify healthcare disparities if not explicitly addressed during model evaluation and deployment.
Additionally, while interpretability via SHAP improves transparency, it does not guarantee clinical correctness, as feature attribution reflects model behavior rather than causal relationships. Therefore, explanations should be interpreted as decision-support aids rather than definitive clinical reasoning tools.
Collectively, these findings support the adoption of a multi-criteria evaluation paradigm in clinical AI systems, where external validation, calibration, fairness, and interpretability are jointly assessed before deployment.
6.4 LIMITATIONS
Several limitations should be acknowledged. First, the datasets used in this study, although widely benchmarked, remain limited in size and diversity, which may restrict the generalizability of subgroup reliability and calibration findings. While external validation was performed using the Cleveland cohort, broader multi-institutional validation is necessary to confirm robustness across heterogeneous clinical environments.
Second, the available datasets do not include all variables required for direct comparison with established clinical risk scoring systems such as Framingham or ACC/AHA models, limiting direct clinical benchmarking.
Third, the framework does not incorporate formal uncertainty quantification methods such as conformal prediction, which could provide stronger probabilistic guarantees and improve safety in high-stakes decision-making environments.
Fourth, although subgroup analysis was performed, the current framework does not include explicit fairness mitigation or subgroup-specific recalibration mechanisms. As a result, observed disparities are identified but not corrected, limiting deployment fairness guarantees.
Finally, no prospective clinical evaluation or clinician-in-the-loop usability study was conducted. Therefore, the proposed system should be interpreted as a validated research prototype rather than a clinically certified decision-support system.
6.5 FUTURE WORK
Future research should extend this reliability-centered framework in several directions. First, validation should be expanded to large-scale, multi-institutional datasets to evaluate robustness under broader demographic and clinical variability. This is essential to assess stability under real-world deployment conditions.
Second, uncertainty-aware learning techniques such as conformal prediction and Bayesian deep learning should be integrated to provide formalized confidence guarantees for individual predictions, improving safety in threshold-based decision-making.
Third, future work should move beyond detection of subgroup disparities toward fairness-aware adaptation mechanisms, where models dynamically adjust calibration across demographic groups to ensure equitable reliability.
Fourth, integrating causal inference methods may help distinguish spurious correlations from clinically meaningful relationships, thereby improving both interpretability and trustworthiness beyond feature attribution methods.
Finally, prospective clinical studies and real-time deployment evaluations are required to assess the impact of the proposed system on clinical workflow, physician decision-making, and patient outcomes. Such studies would enable transition from retrospective validation to continuous monitoring of model drift, calibration degradation, and decision feedback loops in real clinical environments.
7. Conclusion
This study presented a reliability-centered framework for heart disease risk prediction that extends beyond conventional accuracy-driven evaluation. While all models achieved strong internal discrimination performance (AUC ≥ 0.92), the observed differences were small and not statistically significant, as confirmed by DeLong testing (p > 0.05). External validation revealed substantial variability in generalization, with Random Forest achieving the highest external performance (AUC = 0.988, Accuracy = 0.934), while the proposed CatBoost model achieved the highest internal AUC (0.926) but showed reduced external performance (AUC = 0.894). These findings demonstrate that reliance on cross-validation and marginal performance gains alone is insufficient for clinically meaningful model selection.
The proposed approach advances clinical machine learning by integrating discrimination, calibration, statistical robustness, subgroup-aware evaluation, and interpretability within a unified decision-support framework. In particular, the results show that probabilistic reliability is not guaranteed: raw CatBoost probabilities achieved the best calibration performance (Brier score = 0.111, ECE = 0.048), outperforming post-hoc calibration methods. Subgroup analysis further revealed variability in calibration error across patient populations, with higher ECE observed in certain groups (e.g., female patients), emphasizing the importance of fairness-aware evaluation.
Rather than identifying a universally superior predictive model, the findings indicate that the primary contribution lies in the development of a clinically intelligent, interpretable, and deployment-oriented system. This system-level perspective prioritizes reliability, transparency, and robustness under real-world conditions, aligning with the requirements of safe and effective clinical decision support.
Future work should focus on large-scale multi-center validation, integration of uncertainty-aware prediction methods, and prospective clinical evaluation to assess real-world impact. Advancing toward clinically deployable AI systems will require not only improved predictive performance but also rigorous validation, equitable reliability across populations, and seamless integration into clinical workflows.
8. References
- Chen, Tianqi, and Carlos Guestrin. 2016. “XGBoost: A Scalable Tree Boosting System.” Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. https://doi.org/10.1145/2939672.2939785.
- Collins, Gary S., Johannes B. Reitsma, Douglas G. Altman, and Karel G. M. Moons. 2015. “Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis (TRIPOD): The TRIPOD Statement.” Annals of Internal Medicine. https://doi.org/10.7326/M14-0697.
- D’Agostino, Ralph B., Ramachandran S. Vasan, Michael J. Pencina, Philip A. Wolf, and William B. Kannel. 2008. “General Cardiovascular Risk Profile for Use in Primary Care: The Framingham Heart Study. Circulation. https://doi.org/10.1161/circulationaha.107.69957.
- Goff, David C., Donald M. Lloyd-Jones, Glen Bennett, Sean Coady, et al. 2014. “2013 ACC/AHA Guideline on the Assessment of Cardiovascular Risk.” Circulation. https://doi.org/10.1161/01.CIR.0000437741.48606.98.
- Guo, Chuan, Geoffrey Pleiss, Yu Sun, and Kilian Q. Weinberger. 2017. “On Calibration of Modern Neural Networks.” International Conference on Machine Learning (ICML).
- Lundberg, Scott M., and Su-In Lee. 2017. “A Unified Approach to Interpreting Model Predictions.” Advances in Neural Information Processing Systems (NeurIPS).
- Niculescu-Mizil, Alexandru, and Rich Caruana. 2005. “Predicting Good Probabilities with Supervised Learning.” Proceedings of the 22nd International Conference on Machine Learning (ICML).
- Platt, John. 1999. “Probabilistic Outputs for Support Vector Machines and Comparisons to Regularized Likelihood Methods.” In Advances in Large Margin Classifiers.
- Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. 2016. “Why Should I Trust You? Explaining the Predictions of Any Classifier.” Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. https://doi.org/10.1145/2939672.2939778.
- Rudin, Cynthia. 2019. “Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead.” Nature Machine Intelligence 1: 206–215. https://doi.org/10.1038/s42256-019-0048-x.
- Wolff, Robert F., et al. 2019. “PROBAST: A Tool to Assess Risk of Bias and Applicability of Prediction Model Studies.” Annals of Internal Medicine. https://doi.org/10.7326/M18-1376.
- Zadrozny, Bianca, and Charles Elkan. 2002. “Transforming Classifier Scores into Accurate Multiclass Probability Estimates.” Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.
- Bukaita, W., J. R. Jinne, and S. R. Kandula. 2025. “Cardiovascular Disease Prediction Using Machine Learning.” American Journal of Biomedical Science & Research 27 (2). https://doi.org/10.34297/AJBSR.2025.27.003539.
- Ambale-Venkatesh, Bharath, et al. 2017. “Cardiovascular Event Prediction by Machine Learning: The Multi-Ethnic Study of Atherosclerosis.” Circulation Research 121 (9): 1092–1101. https://doi.org/10.1161/CIRCRESAHA.117.311312.
- Beam, Andrew L., and Isaac S. Kohane. 2018. “Big Data and Machine Learning in Health Care.” JAMA 319 (13): 1317–1318. https://doi.org/10.1001/jama.2017.18391.
- Kelly, Christopher J., et al. 2019. “Key Challenges for Delivering Clinical Impact with Artificial Intelligence.” BMC Medicine 17: 195. https://doi.org/10.1186/s12916-019-1426-2.
- Khera, Rohan, et al. 2021. “Use of Machine Learning Models to Predict Death After Acute Myocardial Infarction.” JAMA Cardiology 6 (6): 633–641. https://doi.org/10.1001/jamacardio.2021.0122.
- Obermeyer, Ziad, and Ezekiel J. Emanuel. 2016. “Predicting the Future—Big Data, Machine Learning, and Clinical Medicine.” New England Journal of Medicine 375 (13): 1216–1219. https://doi.org/10.1056/NEJMp1606181.
- Rajkomar, Alvin, Jeffrey Dean, and Isaac Kohane. 2019. “Machine Learning in Medicine.” New England Journal of Medicine 380 (14): 1347–1358. https://doi.org/10.1056/NEJMra1814259.
- Samek, Wojciech, Thomas Wiegand, and Klaus-Robert Müller. 2017. “Explainable Artificial Intelligence: Understanding, Visualizing and Interpreting Deep Learning Models.” IEEE Signal Processing Magazine 34 (6): 76–86. https://doi.org/10.1109/MSP.2017.2743538.
- Steyerberg, Ewout W. 2019. Clinical Prediction Models. 2nd ed. Cham: Springer. https://doi.org/10.1007/978-3-030-16399-0.
- Weng, Stephen F., Jenna Reps, Joe Kai, Jonathan M. Garibaldi, and Nisha Qureshi. 2017. “Can Machine Learning Improve Cardiovascular Risk Prediction Using Routine Clinical Data?” PLoS ONE 12 (4): e0174944. https://doi.org/10.1371/journal.pone.0174944.